Bad Banking Behavior
Analyzing Bank Mortgage during the 2008 Housing Bubble
Analyzing Bank Mortgage during the 2008 Housing Bubble
Data Mining Script ¶
Objectives¶
Below contains information on five features: credit score, debt-to-income ratio, loan-to-value ratio, median household income at the 3-digit zip code-level, and the dollar amount change in mortgage loans made 1 year ago and 5 years ago. The latter feature was created by taking total loan amount during a fiscal year quarter for each bank within a 3-digit zip code.
Graphs and tables are made for foreclosures and the five features analyzed. This includes creating graphs for model predictions. Included in the graph data visualizations are GIFs of foreclosures changing over time.
Load Functions¶
# Load functions
%run Functions.ipynb
pd.set_option("display.max_columns", 200)
pd.set_option('display.max_rows', 200)
# Load data
file_to_open = open('..\Data\Pickle\df.pkl', 'rb')
df = pickle.load(file_to_open)
file_to_open.close()
file_to_open = open('..\Data\Pickle\df_load.pkl', 'rb')
df_load = pickle.load(file_to_open)
file_to_open.close()
# Convert Inf values to NA
df = df.replace([np.inf, -np.inf], np.nan)
df_load = df_load.replace([np.inf, -np.inf], np.nan)
# Set up plots
jtplot.style(ticks=True, grid=False)
import plotly.io as pio
from IPython.display import HTML
from PIL import Image
# Rename Columns
df = df.rename(columns={"Original Combined Loan-to-Value (CLTV)": "Loan-to-Value (LTV)",
"Original Debt to Income Ratio": "Debt-to-Income",
"Loan Change (1 Year)": "Loan Change (1 Yr)",
"Loan Change (5 Years)": "Loan Change (5 Yr)",
"Lnlsnet (1 Yr)": "Loan Liabilities (1 Yr)",
"Lnlsnet (5 Yr)": "Loan Liabilities (5 Yr)"})
df_load = df_load.rename(columns={"Original Combined Loan-to-Value (CLTV)": "Loan-to-Value (LTV)",
"Original Debt to Income Ratio": "Debt-to-Income"})
Foreclosure Descriptive Statistics¶
print('Year 2006')
print(df_load.loc[df_load['File Year']==2006, 'Bank'].value_counts())
print('\n')
print('Year 2007')
print(df_load.loc[df_load['File Year']==2007, 'Bank'].value_counts())
print('\n')
print('Year 2008')
print(df_load.loc[df_load['File Year']==2008, 'Bank'].value_counts())
Other is a major catogory
print('Year 2006')
display(Overall_Data(df = df_load, subset = "df_load['File Year']==2006").iloc[:,:2])
print('\n')
print('Year 2007')
display(Overall_Data(df = df_load, subset = "df_load['File Year']==2007").iloc[:,:2])
print('\n')
print('Year 2008')
display(Overall_Data(df = df_load, subset = "df_load['File Year']==2008").iloc[:,:2])
print('\n')
print('All Years')
display(Overall_Data(df = df_load, subset = "df_load['File Year']>=2006").iloc[:,:2])
print('\n')
print('Isolating Other Loans (All Years)')
subset = "(df_load['File Year']>=2006) & (df_load['Bank']=='Other')"
display(Overall_Data(df = df_load, subset = subset).iloc[:,:2])
Other, smaller, banks constitute much fewer foreclosures (5.9%) compared to the big banks. Removing them from the dataset should increase the proportion of foreclosures.
# Drop unused variables
# Variables to drop
dropvars = ['Year', 'Month', 'Region', 'Zero Balance Code',
'Mortgage Insurance Type',
'First Payment', 'Original Loan-to-Value (LTV)']
df = df.drop(labels=dropvars, axis=1)
df = df.filter(regex=r'^(?!Asset).*$')
df = df.filter(regex=r'^(?!Liab).*$')
df = df.filter(regex=r'^(?!Eqtot).*$')
df = df.filter(regex=r'^(?!Dep).*$')
df = df.dropna()
# Variables to drop
dropvars = ['Year', 'Month', 'Zero Balance Code',
'Mortgage Insurance Type',
'First Payment', 'Original Loan-to-Value (LTV)']
df_load = df_load.drop(labels=dropvars, axis=1)
df_load = df_load.dropna()
# Drop other banks
df_load = df_load.loc[df_load['Bank'] != 'Other',:]
# Drop missings in main data
df_new = df_load.loc[df_load['File Year']>=2006,:]
df_old = df_load.loc[df_load['File Year']<2006,:]
subset = df_new.loc[:,'Loan ID'].isin(df.loc[:,'Loan ID'])
df_sub = df_new.loc[subset,:]
df_load = pd.concat([df_old, df_sub], axis=0)
print('Year 2006')
display(Overall_Data(df = df, subset = "df['File Year']==2006").iloc[:,:2])
print('\n')
print('Year 2007')
display(Overall_Data(df = df, subset = "df['File Year']==2007").iloc[:,:2])
print('\n')
print('Year 2008')
display(Overall_Data(df = df, subset = "df['File Year']==2008").iloc[:,:2])
print('\n')
print('All Years')
display(Overall_Data(df = df, subset = "df['File Year']>=2006").iloc[:,:2])
Removing Other, smaller, banks increased foreclosures from 7.7% to 9.7%.
# Quarter Version
YrQtr = {}
Qtr = ('Q1', 'Q2', 'Q3', 'Q4')
Yr = range(2006,2009)
i = 0
for yr in Yr:
for qtr in Qtr:
YrQtr[i] = str(str(yr) + qtr)
i += 1
# Short Version
YrShort = {}
Yr = range(2006,2009)
i = 0
for yr in Yr:
YrShort[i] = str(yr)
i += 1
# Long Version
df_YrLong = {}
YrLong = {}
Yr = range(2001,2009)
i = 0
for yr in Yr:
YrLong[i] = int(yr)
i += 1
print('Number in quarter time series', len(YrQtr))
print('Number in short time series', len(YrShort))
print('Number in long time series', len(YrLong))
# Foreclosures by year
plot_yr = {}
plot_df = pd.DataFrame(index=['Foreclosed (%)'], columns=YrLong.values())
for j in range(len(YrLong)):
plot_yr[j] = Overall_Data(YrQtr = YrLong[j], df = df_load).iloc[1,0]
plot_df.iloc[:,j] = plot_yr[j]
fig, ax = plt.subplots(1, 1, figsize=(16,10))
plt.plot(plot_df.columns, plot_df.iloc[0,:], linewidth=5, alpha=1)
ax.set_title('Foreclosure Rates\n2001 - 2008', fontsize=22)
ax.axis(ymin=0, ymax=11)
ax.set_ylabel('Foreclosures (%)', fontsize=20)
ax.set_xlabel('Year of Loan Approval', fontsize=20)
ax.tick_params(axis='both', labelsize=20)
plt.show()

# Original Mortgage amount by foreclosure by year
plot_yr0 = {}
plot_yr1 = {}
plot_df = pd.DataFrame(index=['Did not Foreclose', 'Foreclosed'], columns=YrLong.values())
for j in range(len(YrLong)):
plot_yr1[j] = Overall_Data(YrQtr = YrLong[j], df = df_load, fmaevars=True).loc['Foreclosed','Original Mortgage Amount']
plot_df.iloc[1,j] = plot_yr1[j]
plot_yr0[j] = Overall_Data(YrQtr = YrLong[j], df = df_load, fmaevars=True).loc['Did not Foreclose','Original Mortgage Amount']
plot_df.iloc[0,j] = plot_yr0[j]
fig, ax = plt.subplots(1, 1, figsize=(16,10))
plt.plot(plot_df.columns, plot_df.iloc[0,:], linewidth=5, alpha=1, color='#595AB7')
plt.plot(plot_df.columns, plot_df.iloc[1,:], linewidth=5, alpha=1, color='#f0ebaa')
ax.set_title('Original Mortgage Amount\n2001 - 2008', fontsize=22)
ax.set_ylabel('Mortgage ($)', fontsize=20)
ax.set_xlabel('Year of Loan Approval', fontsize=20)
ax.axis(ymin=60000, ymax=220000)
ax.tick_params(axis='both', labelsize=20)
ax.legend(plot_df.T.columns, loc='lower right', fontsize=20)
plt.show()

# Foreclosures
Foreclosed = Overall_Data(df = df)
# Graphing target variable
fig = plt.figure(figsize=(15,4))
bars = Foreclosed.loc[:, 'Foreclosed (%)']
bars.plot.barh(color='#ca2c92').invert_yaxis()
plt.title(str('Overall Foreclosure Rate\n2006 - 2008'))
# Labels
ls = bars.values
xs = bars.values
ys = np.array([0, 1])
for x,y,l in zip(xs,ys,ls):
label = "{:.1f}".format(l)
plt.annotate(label, # this is the text
(x,y), # this is the point to label
textcoords="offset points", # how to position the text
xytext=(3,0), # distance from text to points (x,y)
color='white',
fontsize=14,
ha='left') # horizontal alignment can be left, right or center
plt.ylabel('Percentage')
plt.xlim([0,100])
plt.show()

gif_frames = list()
for i in range(len(YrQtr)):
# Foreclosures
Foreclosed = Overall_Data(YrQtr = YrQtr[i], df = df)
# Graphing target variable
fig = plt.figure(figsize=(15,4))
bars = Foreclosed.loc[:, 'Foreclosed (%)']
bars.plot.barh(color='#ca2c92').invert_yaxis()
plt.title(str('Foreclosures for ' + YrQtr[i]), fontsize=22)
# Labels
ls = bars.values
xs = bars.values
ys = np.array([0, 1])
for x,y,l in zip(xs,ys,ls):
label = "{:.1f}".format(l)
plt.annotate(label, # this is the text
(x,y), # this is the point to label
textcoords="offset points", # how to position the text
xytext=(3,0), # distance from text to points (x,y)
color='white',
ha='left') # horizontal alignment can be left, right or center
plt.ylabel('Percentage', fontsize=20)
ax.tick_params(axis='both', labelsize=20)
plt.xlim([0,100])
plt.savefig(str("GIF_Frames/Foreclosures_" + str(i) + ".png"), transparent=False)
plt.close(fig)
gif = Image.open(str("GIF_Frames/Foreclosures_" + str(i) + ".png"))
gif_frames.append(gif)
# Save GIF
gif_frames[0].save('GIF_Frames/Foreclosures.gif', format='GIF', save_all=True,
append_images=gif_frames[1:], optimize=True, duration=900, loop=0)
# Display GIF
HTML('<img src="GIF_Frames/Foreclosures.gif">')

Geographical Representation of Foreclosures¶
State Foreclosures
fig = {}
frames = list()
gif_frames = list()
for i in range(len(YrLong)):
# Foreclosures
State_Foreclosures = df_load.loc[df_load['File Year']==YrLong[i],:] \
.groupby(['Property State']).agg({'Foreclosed': 'mean'})*100
State_Foreclosures = State_Foreclosures.round(1)
# Graph
fig[i] = go.Figure(data=go.Choropleth(
locations=State_Foreclosures.index, # Spatial coordinates
z = State_Foreclosures['Foreclosed'].astype(float), # Data to be color-coded
zmin = 0,
zmax = 30,
locationmode = 'USA-states', # set of locations match entries in `locations`
colorscale = px.colors.sequential.Purples[3:],
marker_line_color=px.colors.sequential.Purples[3],
colorbar_title = "Forclosures (%)"
))
fig[i].update_layout(
title_text = str("Forclosures by State, " + str(YrLong[i])),
geo_scope='usa', # limite map scope to USA
margin={"r":0,"l":0,"b":0}
)
pio.write_image(fig[i], str("GIF_Frames/State_Foreclosures_" + str(YrLong[i]) + ".png"))
gif = Image.open(str("GIF_Frames/State_Foreclosures_" + str(YrLong[i]) + ".png"))
gif_frames.append(gif)
# Save GIF
gif_frames[0].save('GIF_Frames/State_Foreclosures.gif', format='GIF', save_all=True,
append_images=gif_frames[1:], optimize=True, duration=900, loop=0)
# Display GIF
HTML('<img src="GIF_Frames/State_Foreclosures.gif">')
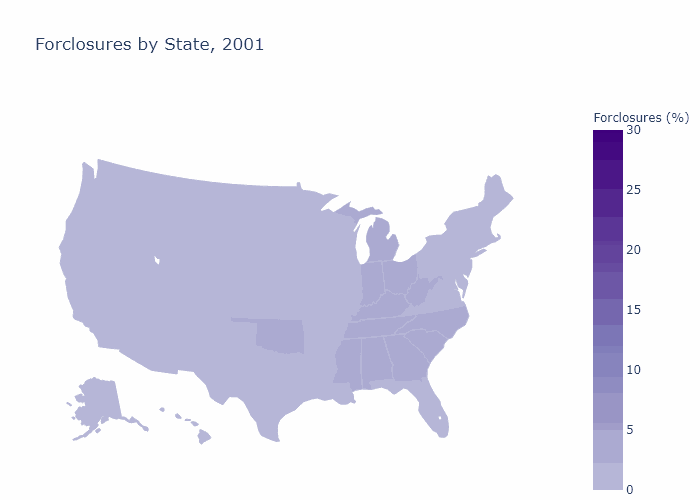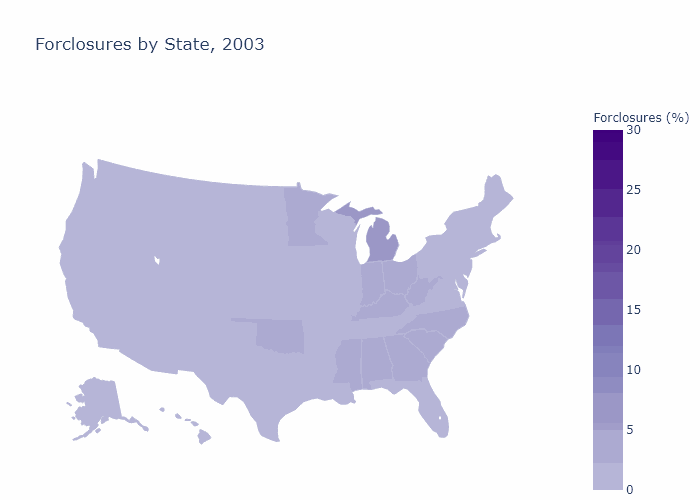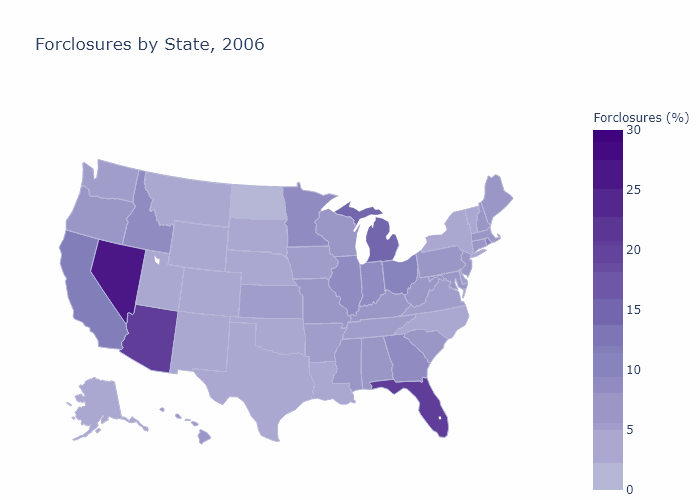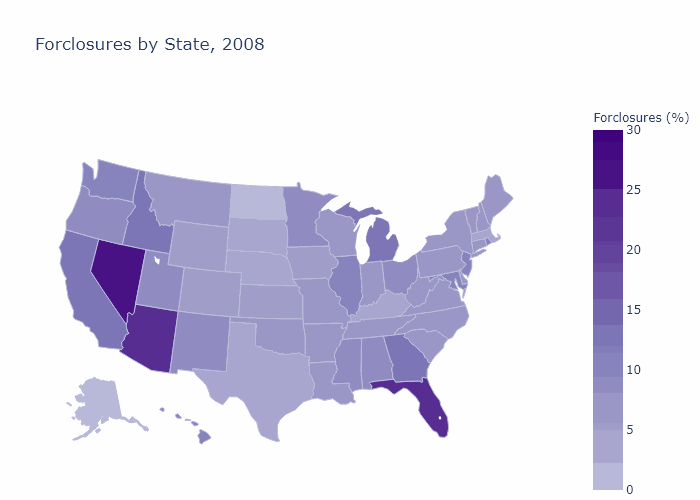
Foreclosures by Zip Code
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
# Import county zipcode crosswalk
crosswalk = pd.read_csv("..\Data\ZIP-COUNTY-FIPS_2017-06.csv",
header = 0)
crosswalk = crosswalk.rename(columns={'ZIP': 'Zip Code', 'COUNTYNAME': 'County', 'STCOUNTYFP': 'FIPS'})
crosswalk = crosswalk.loc[:, ['Zip Code', 'County', 'FIPS']]
crosswalk['Zip 5'] = crosswalk['Zip Code']
crosswalk['Zip Code'] = crosswalk['Zip Code'].astype(str)
crosswalk['Zip Code'] = crosswalk['Zip Code'].str.slice(start=0, stop=-2)
crosswalk['Zip Code'] = crosswalk['Zip Code'].str.ljust(3, '0')
crosswalk['FIPS'] = crosswalk['FIPS'].astype(str)
crosswalk['FIPS'] = crosswalk['FIPS'].str.rjust(5, '0')
fig = {}
frames = list()
gif_frames = list()
for i in range(len(YrLong)):
# Foreclosures
FIPS_Foreclosures = df_load.loc[df_load['File Year']==YrLong[i],:] \
.groupby(['Zip Code']).agg({'Foreclosed': 'mean'})*100
FIPS_Foreclosures = FIPS_Foreclosures.round(1)
FIPS_Foreclosures = FIPS_Foreclosures.reset_index()
FIPS_Foreclosures['Zip Code'] = FIPS_Foreclosures['Zip Code'].astype(int).astype(str)
FIPS_Foreclosures['Zip Code'] = FIPS_Foreclosures['Zip Code'].str.ljust(3, '0')
# Merge
FIPS_Foreclosures = pd.merge(FIPS_Foreclosures, crosswalk, on='Zip Code', how='inner')
# Remove Outliers
FIPS_Foreclosures = FIPS_Foreclosures.loc[FIPS_Foreclosures['Foreclosed']!=100, :]
FIPS_Foreclosures = FIPS_Foreclosures.loc[FIPS_Foreclosures['Foreclosed']!=50, :]
# Graph
fig[i] = go.Figure(data=go.Choropleth(
locations = FIPS_Foreclosures['FIPS'], # Spatial coordinates
z = FIPS_Foreclosures['Foreclosed'].astype(float), # Data to be color-coded
zmin = 0,
zmax = 30,
locationmode = 'geojson-id', # set of locations match entries in `locations`
geojson = counties,
colorscale = px.colors.sequential.Blues[3:],
marker_line_color=px.colors.sequential.Blues[3],
colorbar_title = "Forclosures (%)"
))
fig[i].update_layout(
title_text = str("Forclosures by Zip Code, " + str(YrLong[i])),
geo_scope='usa', # limite map scope to USA
margin={"r":0,"l":0,"b":0}
)
pio.write_image(fig[i], str("GIF_Frames/Zip_Foreclosures_" + str(YrLong[i]) + ".png"))
gif = Image.open(str("GIF_Frames/Zip_Foreclosures_" + str(YrLong[i]) + ".png"))
gif_frames.append(gif)
# Save GIF
gif_frames[0].save('GIF_Frames/Zip_Foreclosures.gif', format='GIF', save_all=True,
append_images=gif_frames[1:], optimize=True, duration=900, loop=0)
# Display GIF
HTML('<img src="GIF_Frames/Zip_Foreclosures.gif">')
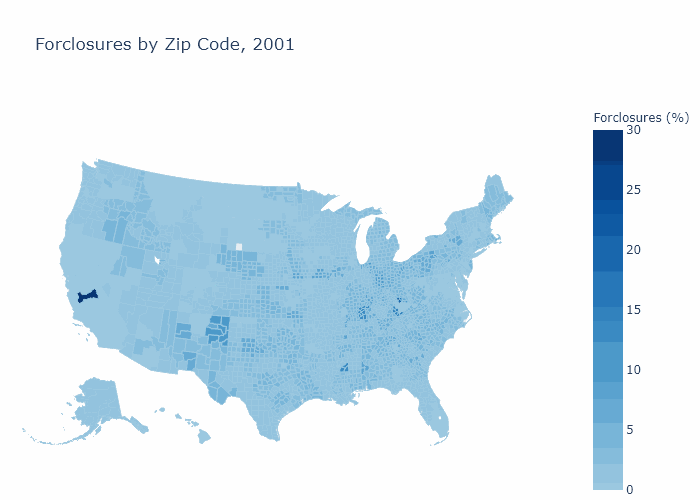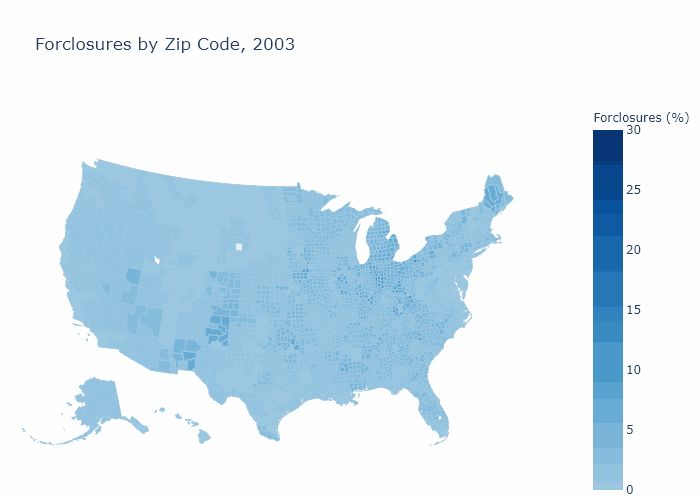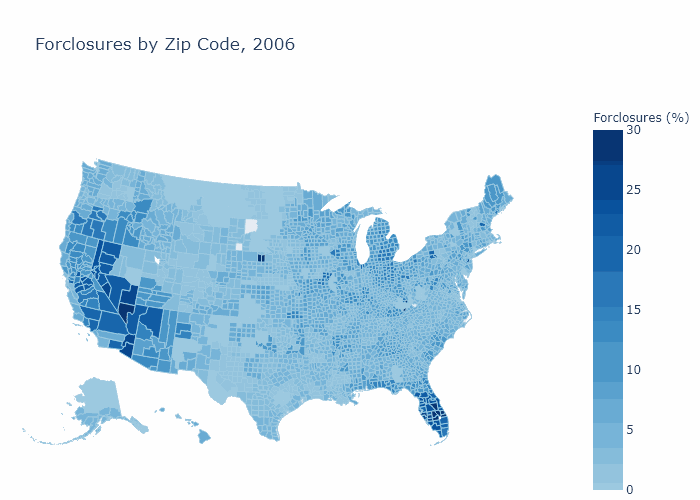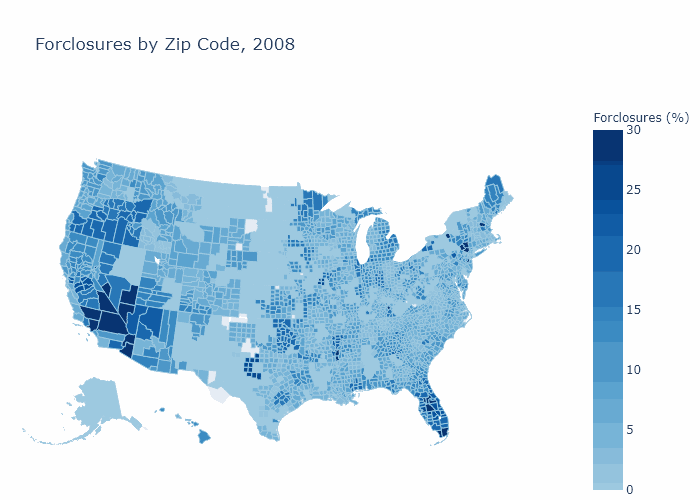
Bank Descriptive Statistics¶
# Bank represented
Banks = Bank_Data(df = df)
Banks
# Feautures per Bank
Banks = Bank_Data(df = df, allvars = True)
Banks
bnk_size = Banks[['Bank (N)']].sort_values(by=['Bank (N)'])
fig, ax = plt.subplots(1, 1, figsize=(15,7))
plt.bar(bnk_size.index, bnk_size.loc[:,'Bank (N)'], color = '#002855')
plt.xticks(rotation=90)
ax.tick_params(axis='both', labelsize=20)
plt.title('Number of Loans by Bank\n2006 - 2008', fontsize=22)
plt.xlabel('Large Lending Banks', fontsize=20)
plt.show()

Foreclosures¶
# Worst actor
worst_actor = pd.DataFrame()
for i in range(len(YrShort)):
print(YrShort[i])
Banks_short = Bank_Data(YrQtr = YrShort[i], df = df_load, rounding = 5)
tbl = search_Banks('Foreclosed (%)', df = Banks_short, func = max)
tbl['Foreclosed (%)'] = tbl['Foreclosed (%)'].round(1)
display(tbl)
tbl = tbl.reset_index()
tbl.index = [YrShort[i]]
worst_actor = pd.concat([worst_actor, tbl], axis = 0)
print('')
print('Overall')
Banks_short = Bank_Data(df = df_load.loc[df_load['File Year']>=2006,:], rounding = 5)
tbl = search_Banks('Foreclosed (%)', df = Banks_short, func = max)
tbl['Foreclosed (%)'] = tbl['Foreclosed (%)'].round(1)
display(tbl)
tbl = tbl.reset_index()
tbl.index = ['Overall']
worst_actor = pd.concat([worst_actor, tbl], axis = 0)
# Best actor
best_actor = pd.DataFrame()
for i in range(len(YrShort)):
print(YrShort[i])
Banks_short = Bank_Data(YrQtr = YrShort[i], df = df_load, rounding = 5)
tbl = search_Banks('Foreclosed (%)', df = Banks_short, func = min)
tbl['Foreclosed (%)'] = tbl['Foreclosed (%)'].round(1)
display(tbl)
tbl = tbl.reset_index()
tbl.index = [YrShort[i]]
best_actor = pd.concat([best_actor, tbl], axis = 0)
print('')
print('Overall')
Banks_short = Bank_Data(df = df_load.loc[df_load['File Year']>=2006,:], rounding = 5)
tbl = search_Banks('Foreclosed (%)', df = Banks_short, func = min)
tbl['Foreclosed (%)'] = tbl['Foreclosed (%)'].round(1)
display(tbl)
tbl = tbl.reset_index()
tbl.index = ['Overall']
best_actor = pd.concat([best_actor, tbl], axis = 0)
worst_best_tbl = pd.concat([worst_actor, best_actor], axis=1)
header = [np.array(['Worst Actors','Worst Actors','Best Actors','Best Actors']),
np.array(worst_best_tbl.columns)]
pd.DataFrame(worst_best_tbl.values, index = worst_best_tbl.index, columns = header )
Foreclosures per Bank¶
plt.close()
gif_frames = []
plot_yr = {}
plot_df = pd.DataFrame(index=Banks.index, columns=YrLong.values())
# Foreclosure by bank line chart
for j in range(len(YrLong)):
plot_yr[j] = pd.DataFrame(Bank_Data(YrQtr = YrLong[j], df = df_load).loc[:, 'Foreclosed (%)'])
plot_yr[j][plot_yr[j]==0] = np.nan
plot_yr[j] = plot_yr[j].rename(columns={'Foreclosed (%)': YrLong[j]})
plot_df.loc[:,YrLong[j]] = plot_yr[j].loc[:,YrLong[j]]
# Interpolate missing years
for j in range(plot_df.shape[1]):
plot_df.T.iloc[:,j] = plot_df.T.iloc[:,j].astype(float).interpolate(method='linear')
plot_dfs = pd.DataFrame(index=Banks.index, columns=YrLong.values()).T
plt.rcParams['figure.figsize']=(16,10)
for j in range(len(plot_dfs.columns)):
for i in range(len(plot_dfs.index)):
plot_dfs.iloc[:i+1,j] = plot_df.T.iloc[:i+1,j]
fig, ax = plt.subplots()
ax.plot(plot_dfs.index, plot_dfs, linewidth=5, alpha=1)
plt.gca().set_prop_cycle(None)
ax.plot(plot_df.T.index, plot_df.T, linewidth=2, alpha=0.33)
ax.set_title('Bank Foreclosure Rates\n' + plot_dfs.columns[j] + ' ' + str(YrLong[i]), fontsize=22)
plt.axis(ymin=0, ymax=14)
ax.tick_params(axis='both', labelsize=20)
ax.set_ylabel('Foreclosures (%)', fontsize=20)
ax.set_xlabel('Year of Loan Approval', fontsize=20)
ax.legend(plot_df.T.columns, loc='lower right', fontsize=16)
plt.savefig(str("GIF_Frames/Bank_Foreclosures_Yr_" + plot_dfs.columns[j] + '_' + str(YrLong[i]) + ".png"), transparent=False)
plt.close(fig)
gif = Image.open(str("GIF_Frames/Bank_Foreclosures_Yr_" + plot_dfs.columns[j] + '_' + str(YrLong[i]) + ".png"))
gif_frames.append(gif)
# Save GIF
gif_frames[0].save('GIF_Frames/Bank_Foreclosures_Yr.gif', format='GIF', save_all=True,
append_images=gif_frames[1:], optimize=True, duration=200, loop=0)
# Display GIF
HTML('<img src="GIF_Frames/Bank_Foreclosures_Yr.gif">')
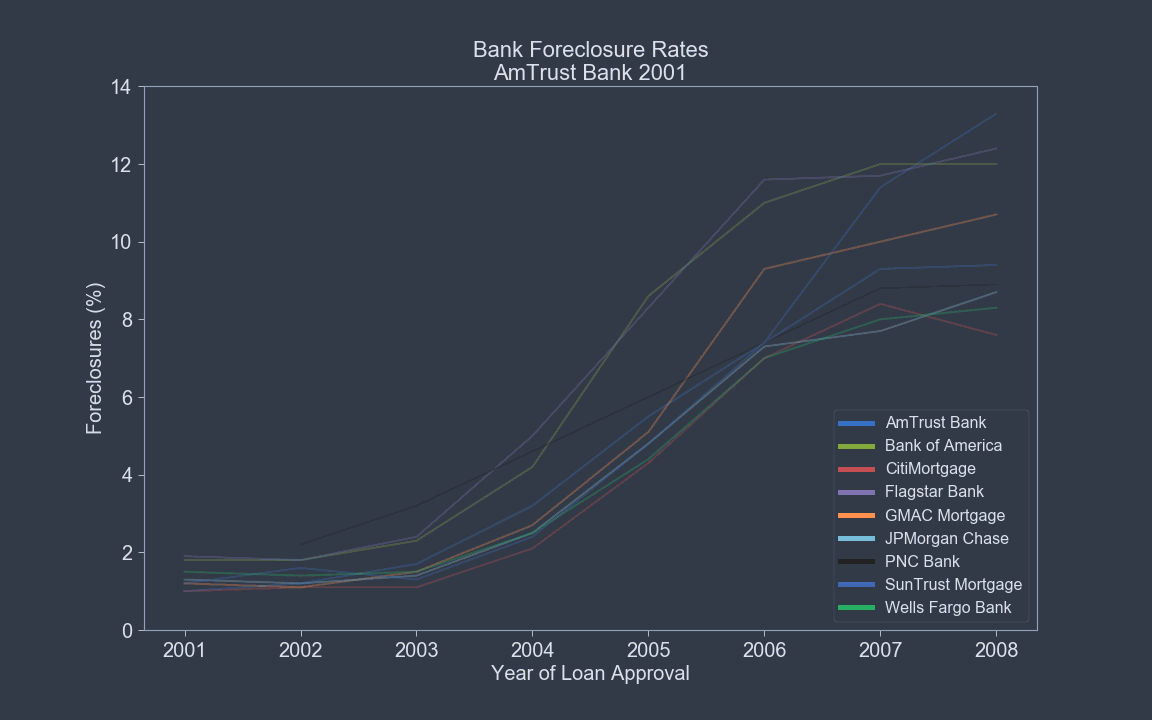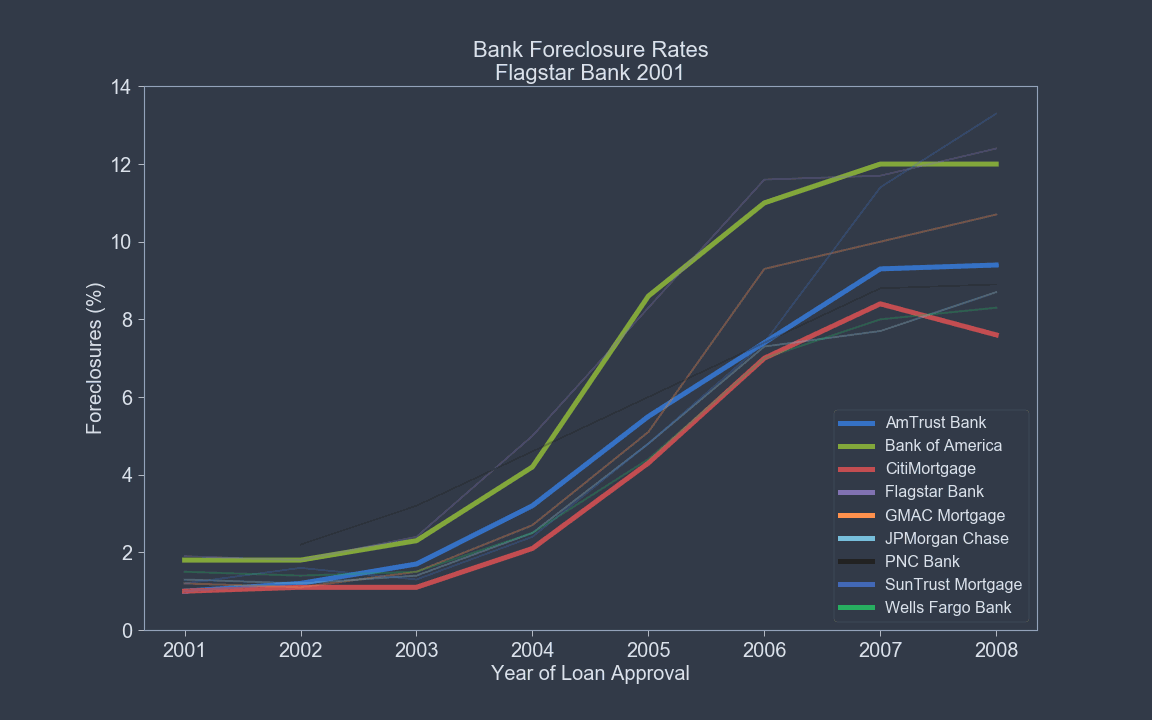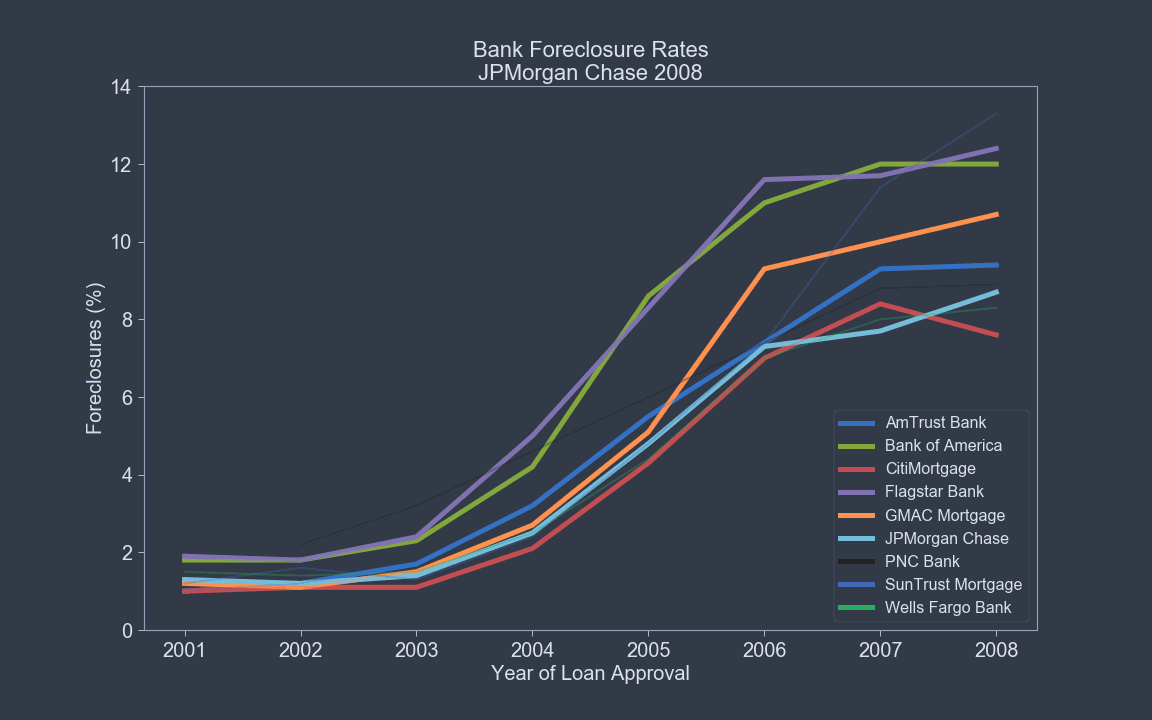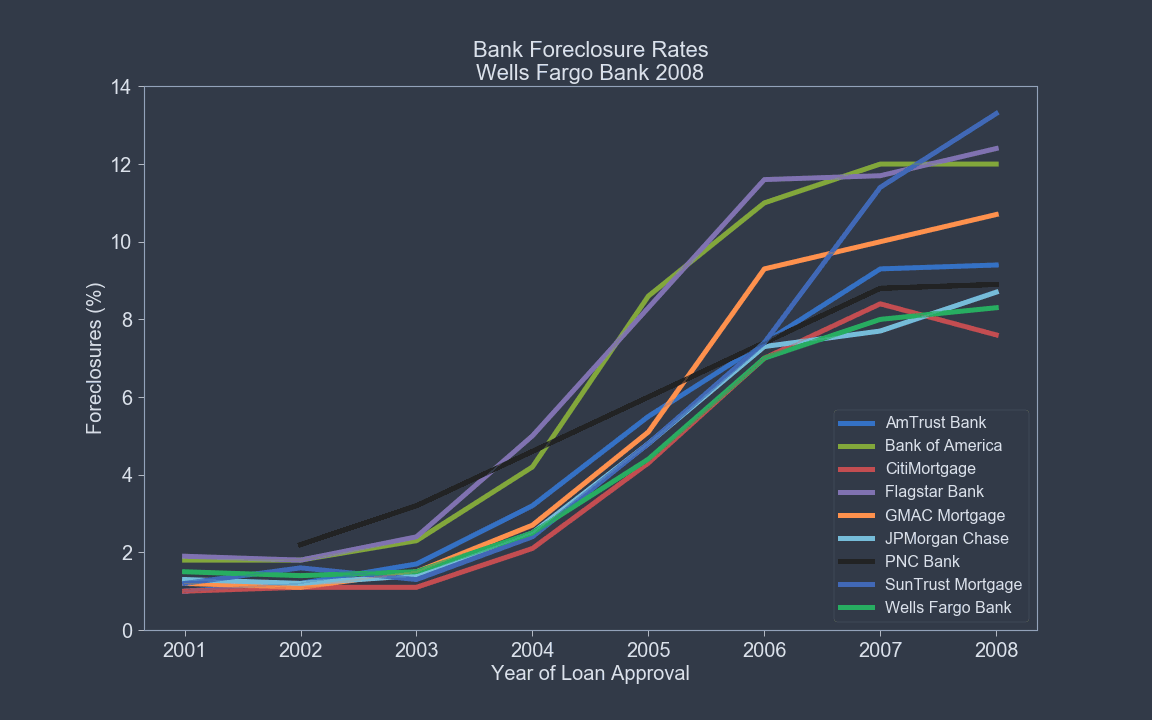
Features Likely to Define Foreclosures¶
# Load predicted probabilities
## Improved assumptions
improved = pickle.load(open("..\Data\Pickle\pred_votes_improved.pkl", "rb"))[0]
improved_values = pickle.load(open("..\Data\Pickle\pred_votes_improved.pkl", "rb"))[1]
best = pickle.load(open("..\Data\Pickle\pred_votes_improved.pkl", "rb"))[2]
best_values = pickle.load(open("..\Data\Pickle\pred_votes_improved.pkl", "rb"))[3]
## Weakened assumptions
weakened = pickle.load(open("..\Data\Pickle\pred_votes_weakened.pkl", "rb"))[0]
weakened_values = pickle.load(open("..\Data\Pickle\pred_votes_weakened.pkl", "rb"))[1]
worst = pickle.load(open("..\Data\Pickle\pred_votes_weakened.pkl", "rb"))[2]
worst_values = pickle.load(open("..\Data\Pickle\pred_votes_weakened.pkl", "rb"))[3]
Credit Score¶
feature_density('Credit Score', bins=None, l_xlim=300, r_xlim=850)

credit_score = Bank_Data(df = df, allvars = True)[['Credit Score']]
bank_rank_gph('Credit Score', df, credit_score, b_ylim=300)

best_worst_gph('Credit Score', df = credit_score, l_xlim=300)

best_worst_density('Credit Score', df, credit_score, bins=None, l_xlim=300, r_xlim=850)


Predictions¶
changed_assumptions_tbl('Credit Score', improved, weakened)
predicted_gph('Credit Score', proba = improved, proba_value = improved_values)
predicted_gph('Credit Score', proba = weakened, proba_value = weakened_values,
func = [min, max], improved=False)


Debt to Income¶
feature_density('Debt-to-Income', bins=20, l_xlim=0, r_xlim=65)

dti = Bank_Data(df = df, allvars = True)[['Debt-to-Income']]
bank_rank_gph('Debt-to-Income', df, dti)

best_worst_gph('Debt-to-Income', df = dti, func = [min, max])

best_worst_density('Debt-to-Income', df, dti, func = [min, max],
bins = 20, l_xlim=0, r_xlim=65)


Predictions¶
changed_assumptions_tbl('Debt-to-Income', improved, weakened)
predicted_gph('Debt-to-Income', proba = improved, proba_value = improved_values)
predicted_gph('Debt-to-Income', proba = weakened, proba_value = weakened_values,
func = [min, max], improved=False)


Combined Loan to Value¶
feature_density('Loan-to-Value (LTV)', bins=None, l_xlim=0, r_xlim=100)

cltv = Bank_Data(df = df, allvars = True)[['Loan-to-Value (LTV)']]
bank_rank_gph('Loan-to-Value (LTV)', df, cltv)

best_worst_gph('Loan-to-Value (LTV)', df = cltv, func = [min, max])

best_worst_density('Loan-to-Value (LTV)', df, cltv, func = [min, max],
bins=None, l_xlim=0, r_xlim=100)


Predictions¶
changed_assumptions_tbl('Loan-to-Value (LTV)', improved, weakened)
predicted_gph('Loan-to-Value (LTV)', proba = improved, proba_value = improved_values)
predicted_gph('Loan-to-Value (LTV)', proba = weakened, proba_value = weakened_values,
func = [min, max], improved=False)


Median Household Income¶
feature_density('Median Household Income', l_xlim=20000, r_xlim=110000)

mhi = Bank_Data(df = df, allvars = True)[['Median Household Income']]
bank_rank_gph('Median Household Income', df, mhi)

best_worst_gph('Median Household Income', df = mhi)

best_worst_density('Median Household Income', df, mhi, l_xlim=20000, r_xlim=110000)


Predictions¶
changed_assumptions_tbl('Median Household Income', improved, weakened)
predicted_gph('Median Household Income',
proba = improved, proba_value = improved_values)
predicted_gph('Median Household Income', func = [min, max],
proba = weakened, proba_value = weakened_values, improved=False)


Best and worst assumptions illustration
changed_assumptions_tbl('Median Household Income', best, worst)
predicted_gph('Median Household Income',
proba = best, proba_value = best_values)
predicted_gph('Median Household Income', func = [min, max],
proba = worst, proba_value = worst_values, improved=False)


Loan Change¶
for v in ['Loan Change (1 Yr)', 'Loan Change (5 Yr)']:
feature_density(v, l_xlim=-100000, r_xlim=100000)


lc1 = Bank_Data(df = df, allvars = True)[['Loan Change (1 Yr)']]
bank_rank_gph('Loan Change (1 Yr)', df, lc1)
lc5 = Bank_Data(df = df, allvars = True)[['Loan Change (5 Yr)']]
bank_rank_gph('Loan Change (5 Yr)', df, lc5)


best_worst_gph('Loan Change (1 Yr)', df = lc1, func = [min, max])
best_worst_gph('Loan Change (5 Yr)', df = lc5, func = [min, max])


best_worst_density('Loan Change (1 Yr)', df, lc1, func = [min, max],
l_xlim=-100000, r_xlim=100000)
best_worst_density('Loan Change (5 Yr)', df, lc5, func = [min, max],
l_xlim=-100000, r_xlim=100000)




Predictions¶
changed_assumptions_tbl('Loan Change (1 Yr)', improved, weakened)
predicted_gph('Loan Change (1 Yr)',
proba = improved, proba_value = improved_values)
predicted_gph('Loan Change (1 Yr)', func = [min, max],
proba = weakened, proba_value = weakened_values, improved=False)


lc_tbl = changed_assumptions_tbl('Loan Change (5 Yr)', improved, weakened)
lc_tbl.columns = [['Foreclosures', 'Loan Change', 'Loan Change'],
['(2006-2008)', 'Improved', 'Weakened']]
lc_tbl
# Update assumption order
improved_values['Loan Change (5 Yr)'] = [improved_values['Loan Change (1 Yr)'][1]]
weakened_values['Loan Change (5 Yr)'] = [weakened_values['Loan Change (1 Yr)'][1]]
predicted_gph('Loan Change (5 Yr)',
proba = improved, proba_value = improved_values)
predicted_gph('Loan Change (5 Yr)', func = [min, max],
proba = weakened, proba_value = weakened_values, improved=False)

